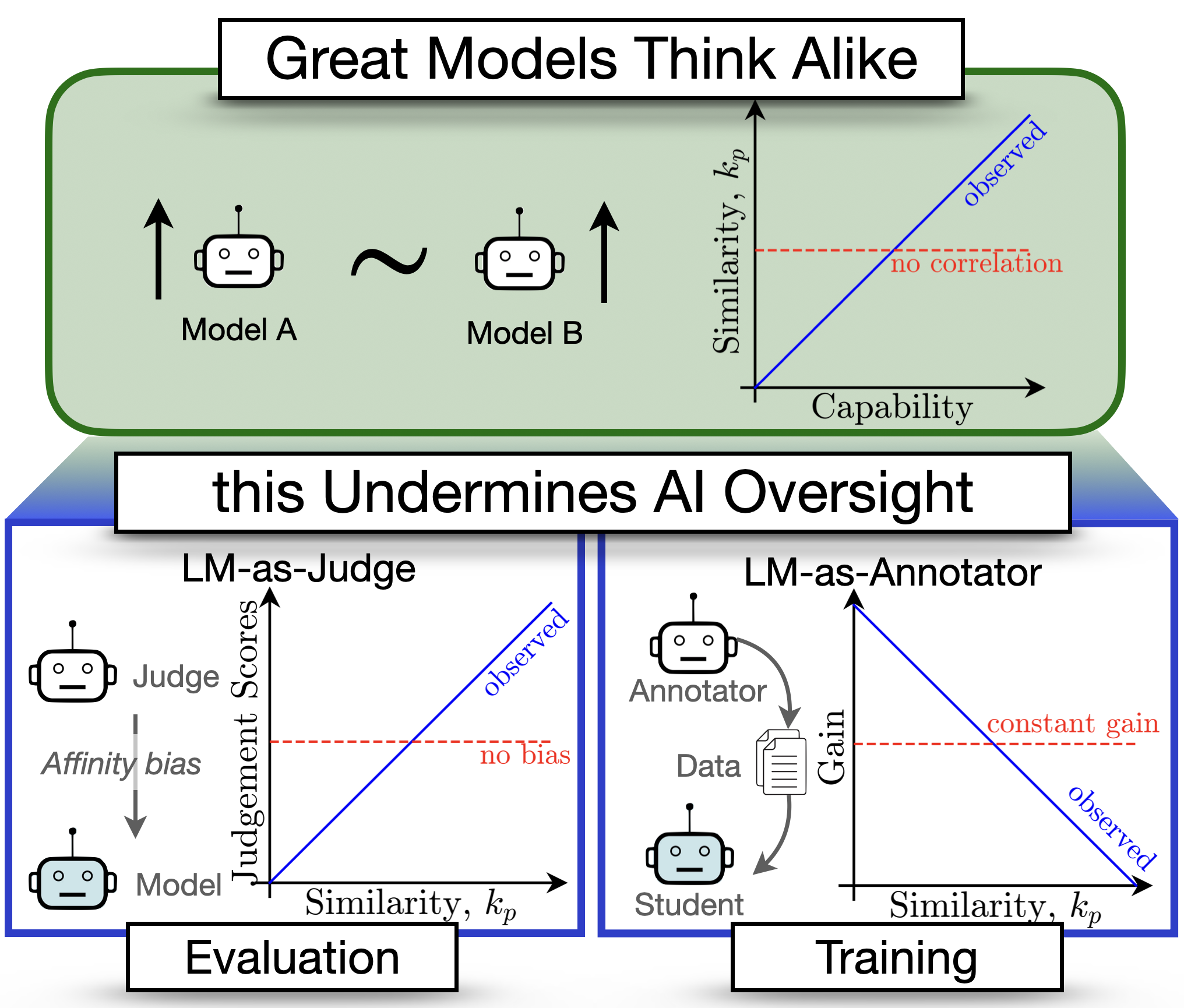
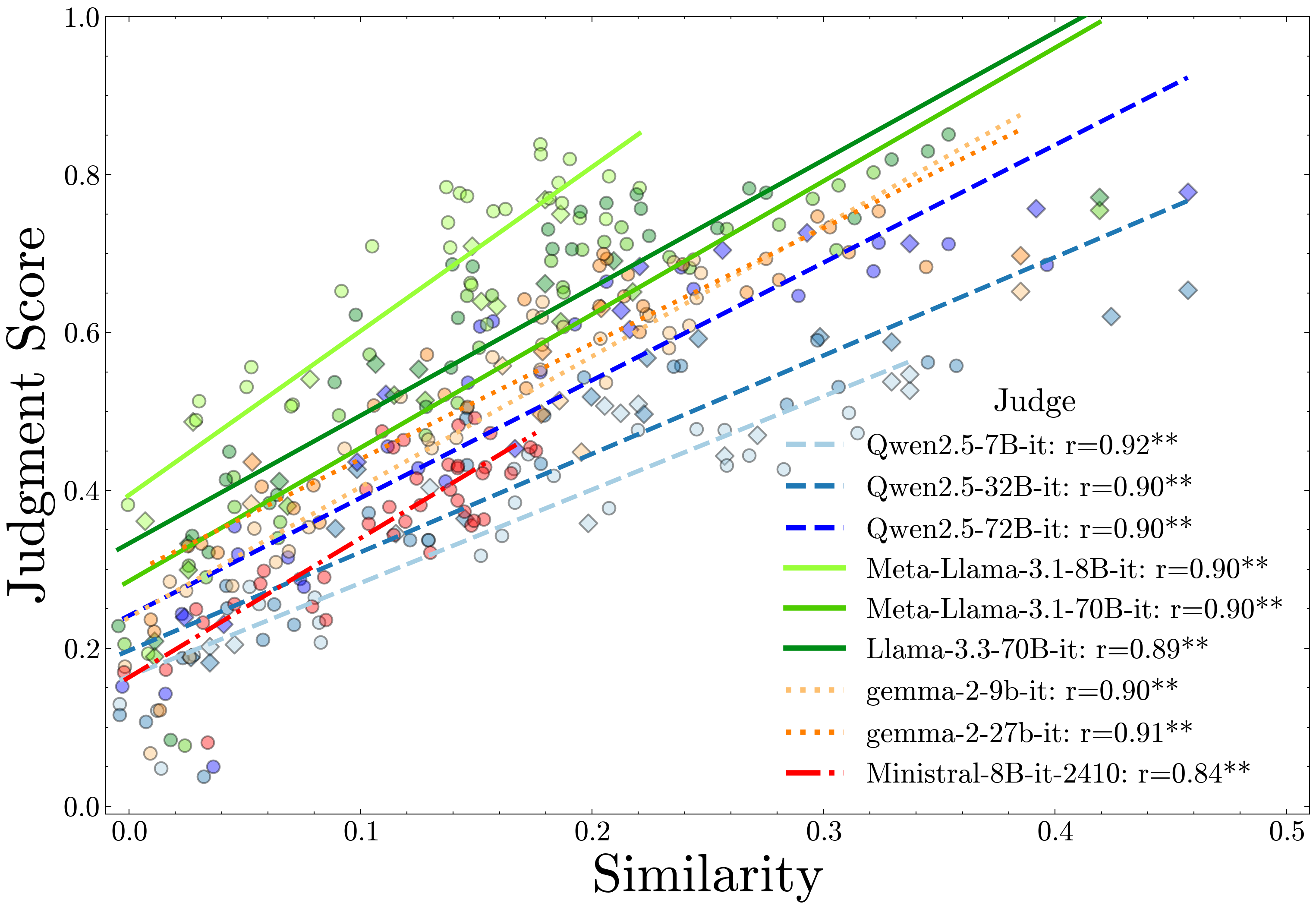
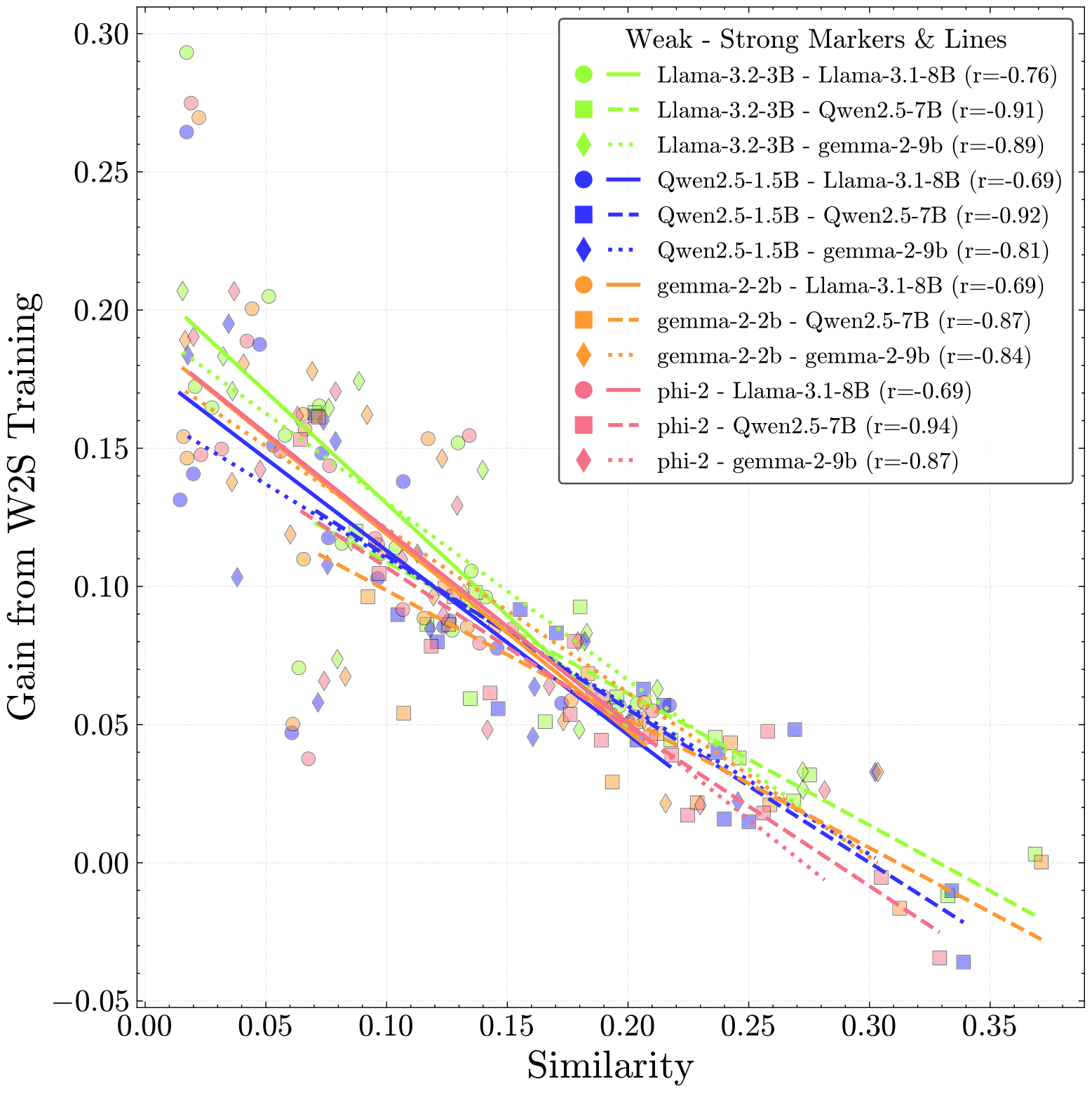
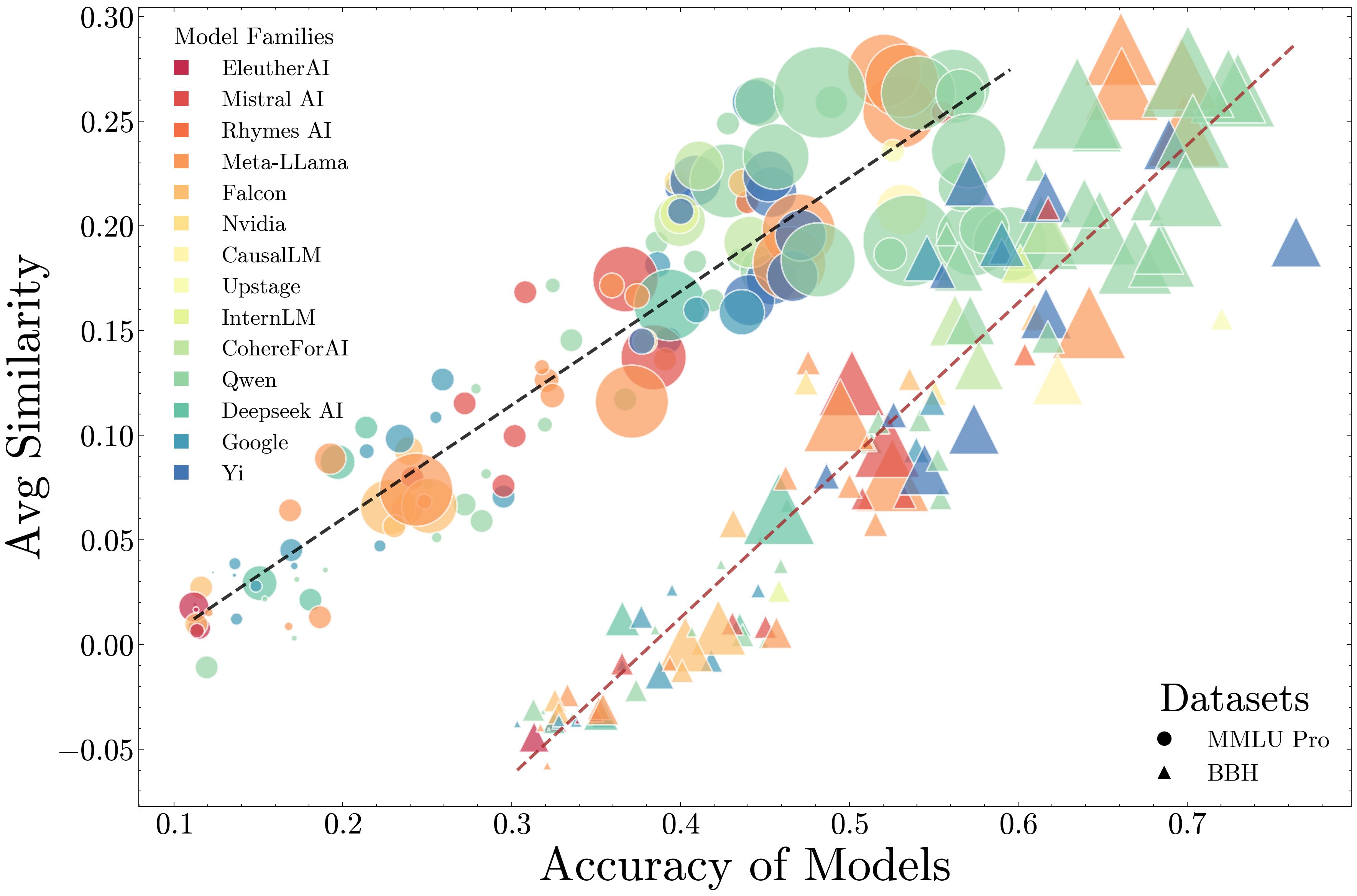
As Language Model (LM) capabilities advance, evaluating and supervising them at scale is getting harder for humans. There is hope that other language models can automate both these tasks, which we refer to as AI Oversight. We study how model similarity affects both aspects of AI oversight by proposing Chance Adjusted Probabilistic Agreement (CAPA): a metric for LM similarity based on overlap in model mistakes. Using CAPA, we first show that LLM-as-a-judge scores favor models similar to the judge, generalizing recent self-preference results. Then, we study training on LM annotations, and find complementary knowledge between the weak supervisor and strong student model plays a crucial role in gains from weak-to-strong generalization. As model capabilities increase, it becomes harder to find their mistakes, and we might defer more to AI oversight. However, we observe a concerning trend -- model mistakes are becoming more similar with increasing capabilities, pointing to risks from correlated failures. Our work underscores the importance of reporting and correcting for model similarity, especially in the emerging paradigm of AI oversight.
We propose a new metric, Chance Adjusted Probabilistic Agreement, or CAPA, which has three key properties: (1) Two models with 90% accuracy have much lesser scope to disagree than two models with 50% accuracy. CAPA adjusts for chance agreement of two independent models with the given accuracies. (2) When both models are wrong, they can still disagree. CAPA compares sample-wise predictions instead of sample-wise correctness. (3) Models provide probabilistic predictions, CAPA incorporates this information.
| Metric | Adjusts for Accuracy |
Distinguishes different mistakes |
Incorporates Probabilities |
|---|---|---|---|
| %Flips = 1 - cobs | ❌ | ❌ | ❌ |
| Cohen's κ, Scott's π, Fleiss κ | ❌ | ✅ | ❌ |
| %Agreement | ❌ | ✅ | ❌ |
| Error Consistency | ✅ | ❌ | ❌ |
| Pearson / Matthew's Correlation of Errors | ✅ | ❌ | ❌ |
| Divergence metrics like KL, JSD | ❌ | ✅ | ✅ |
| CAPA (κp) - Ours | ✅ | ✅ | ✅ |
For CAPA's mathematical definition and theoretical properties, checkout our paper. You compute similarities between different models using our interactive tool!
@misc{goel2025greatmodelsthinkalike,
title={Great Models Think Alike and this Undermines AI Oversight},
author={Shashwat Goel and Joschka Struber and Ilze Amanda Auzina and Karuna K Chandra and Ponnurangam Kumaraguru and Douwe Kiela and Ameya Prabhu and Matthias Bethge and Jonas Geiping},
year={2025},
eprint={2502.04313},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2502.04313},
}